
What Problems are Being Solved by the Top NGS Bioinformaticians Today?
My PhD adviser often said - “If you want to know what the top physicists were doing two years back, read their papers. If you are interested in the problems they are working on today, go to conferences and attend their talks.” That was before the twitter and arxiv days. Speaking of arxiv, in 1997, I had to spend quite a bit of effort to convince him to post our papers online prior to publication.
Today there is a better place than conferences to check to know what the top bioinformaticians are working on and that place is github. Here are a few snapshots.
1. Streaming counting of k-mers
Jared Simpson is working with mgbarsky on ‘streamcount’ project.
This is a program which counts occurences of k-mers (strings of length k characters) in an arbitrarily large input.
The program first takes a set of pattern strings, breaks them into k-mers, and builds from this set of patterns a keyword tree with suffix links (see Aho- Corasick algorithm). This keyword tree is serialized to disk, to stream any input file against it.
In the second part, each line of each input file is streamed through the keyword tree and the counters of the corresponding k-mers for this file are collected and serialized to disk.
2. de Bruijn Graph in FM index

Github page does not have much information other than a wrapper class. Authors are staying tight-lipped about the method and the reason is possibly 3 and 4 below.
3. Heng Li - Fermi2 (FM index with dBG again)
Note: fermi2 is in fact not the successor of fermi. It drops the assembly component in fermi and focuses on the exploration of FMD-index as a graph. It relies on fermi or ropebwt2 for index construction.
Fermi2 is fairly incomplete, but some components are usable and to some extend better than fermi equivalent.
4. Heng Li - ropebwt2
RopeBWT2 is an experimental tool for constructing the FM-index for a collection of DNA sequences. It works by incrementally inserting multiple sequences into an existing pseudo-BWT position by position, starting from the end of the sequences. This algorithm can be largely considered a mixture of BCR and dynamic FM-index. Nonetheless, ropeBWT2 is unique in that it may implicitly sort the input into reverse lexicographical order (RLO) or reverse- complement lexicographical order (RCLO) while building the index. Suppose we have file seq.txt in the one-sequence-per-line format.
5. Shaun Jackman - Samskrit
Tools to manipulate SAM and BAM files
Samskrit = Sanskrit + SAM scripts. Get it? Funny!
Tools
samskrit-swap: Swap the roles of the query and target sequence
You get the general idea. Everyone is looking for ways to randomly retrieve reads out of large sequencing libraries based on given criteria.
What else is hot?
-———————————————————
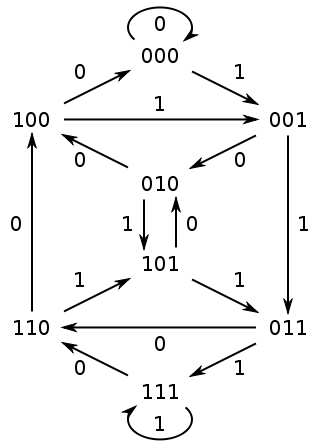
Those interested in learning about a method to combine de Bruijn graph and BWT are encouraged to read Alex Bowe’s introductory blog post.