
Why Computer Science Professors Dislike Hash Functions
We have been going through various web-based resources on high-quality hash functions and made a startling discovery. None of the good websites was maintained by the members of computer science departments at top universities or even second-rank universities. Based on our highly anecdotal evidence, computer science professors stopped thinking about hash functions many decades back. That seemed puzzling, because in the world where it matters, research on hash function still attracts big money.
We were thinking about the apparent anomaly and came up with the following explanation. ‘Hash functions’ destroy the fantasy called ‘computer science’, and therefore computer science professors do not want to acknowledge their continued development. By promoting a researcher working on novel hash functions, they will be doing disservice to their motto of ‘universal programming’ and ‘commodity hardware’. Computer science will not be seen as ‘science’ but be ‘looked down upon’ as another engineering field. Therefore, the best strategy is to marginalize advancements on hash functions.
Best Websites on Hash Functions
Before we continue with that line of thinking, let us present the evidence. We will be happy, if readers can provide evidence disputing our claim. Here are the top hash function-related websites and success stories found by us.
1. Keccak won the NIST competition as SHA-3 or top cryptographic hash function. It was developed by Guido Bertoni, Joan Daemen, Michal Peeters and Gilles Van Assche, four persons working in two semiconductor companies, not computer science researchers as we expected them to be.
2. Bob Jenkins’ website is web’s best resource on Hash functions. Here is how Bob describes himself.
A year at UC Berkeley in the doctoral program for theoretical computer science convinced Bob that he didn’t want to become a professor.
3. Bob Jenkins’ 1997 paper, which he continually updates with latest information, is possibly the best single paper on non-crypto hash functions. It was published in Dr Dobbs, not one of the popular CS journals.
4. Murmurhash was the latest big advancement in the hash function world. It was published in Austin Appleby’s personal blog, but a not-so-insignificant company hired him for his research (see below).
5. Google has taken over Murmurhash project and maintains another highly informative website (smhasher) comparing the performances of various hash functions.
6. Two other informative website on non-crypto hash functions are maintained by dedicated non-academics -
Non-Cryptographic Hash Function Zoo
General Purpose Hash Function Algorithms
Academic Literature
We did some web search to find out respectable technical publications on hash functions. The most cited one came from China and is worth reading, especially by those Americans, who want to fund giant military projects at the cost of math research. It was published in 2005 and already received 1100 highly deserved citations.
How to Break MD5 and Other Hash Functions - Xiaoyun Wang and Hongbo Yu
Another paper from last 15 years with over 200 citations was
Merkle-Damgard? Revisited : how to Construct a Hash Function
However, it was based on MerkleDamgrd construction described in Ralph Merkle’s 1979 Ph.D. thesis. Other top hits were mostly from 1970s and 80s as well. It seems like the excitement stopped after Ron Rivest’s work on RSA in early 90s.
A Secure One-way Hash Function Built from DES - Robert S. Winternitz, ISL, St anford
(1996) Tiger: A fast new hash function - Ross Anderson, Eli Biham - Purchase on Springer.com
$29.95 / 24.95 / 19.95 + VAT
Why Computer Science Academics Do not Like Hash Functions
As PW Anderson argued in his ‘More is Different’ article, every academic field is based on a set of abstractions. ‘Computer science’ is an abstraction built on top of computer hardware, and hash function is the direct connection between hardware and computer science. The von Neumann architecture used by computer science uses linear memory. A hash function is the abstraction to go from large input set to small linear memory.
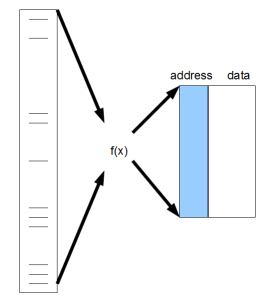
To the dismay of computer science researchers, hash functions must be highly hardware dependent. As we said earlier, that goes against the notions of ‘universal programming algorithms’ or ‘commodity hardware’. For example, if Intel decides to put CRC32 or Murmurhash as part of their instruction code, relative performances of all programs using those hash functions will change substantially. The same is true for new kind of data. Hash functions tested for English text may not be good for bioinformatics text. There is no universal ‘one-size-fit-all’ hash function. Unless computer hardware and data stop changing, research on hash functions will continue to find ‘better’ hash functions.
Is CRC32 a Good Hash Function?
Bob Jenkins says yes, and the following threads say no.
Can CRC32 be used as a hash function?
Can one construct a good hash function using CRC32C as a base
One thing for sure, Intel’s adoption of CRC32 as part of SSE 4.2 changes many performance comparisons.
Edit.
Ruibang Luo, author of BGI’s SOAPdenovo assembler, chimed in:
In your latest blog post “Why computer scientists dislike hash functions”, the reference website showing that CRC32 is not suitable for hash function at all and failed all avalanche tests is inconsistent with my test (somebody mentioned that they have used buggy CRC32 table but I haven’t checked that). A test using genome text (both ascii and 2-bit encoding) instead of using English text should be more informative and accurate. According to my experience, different state of the art hash functions including murmurhash, cityhash, spookyhash, Jenkins and CRC32c do not make too much difference to the evenness of 2-bit encoding.
Choosing a Good Hash Function
For Bioinformatics, we do not need crypto hash functions. Among non-crypto ones, SpookyHash and Murmur3 are currently the hottest closely followed by Jenkins and City. Spooky hash is Bob Jenkins’ latest contribution. Cityhash is being developed by Google as an improvement over Murmur3. The following website presents very good comparative analysis, but do keep in mind that the tests were done on English text and Intel architecture. If you move to new kind of text and new hardware architecture, results will change.
Choosing a Good Hash Function, Part 3
Choosing a Good Hash Function, Part 2
What is a good hash function for genomic data?